
Agents in production, part 1: the 20-person startup
A team at a 20-person startup added an LLM-powered feature to their existing API in two days. It worked in staging. In production, the first day of real traffic brought cascading 504s, a dead queue, and their on-call engineer debugging at 2 AM. The LLM code was three lines. The incident took six hours to resolve.
What went wrong is not obvious until you look at the architecture before and after the LLM was added. The original system was solid. The LLM was wired in as if it were a fast database call. It is not.
This is part 1 of a series on running AI agents in production. It covers the architecture that most 20-person startups already have, why it breaks the moment you add a synchronous LLM call, and the specific changes that fix it.
What the 20-person startup already has right
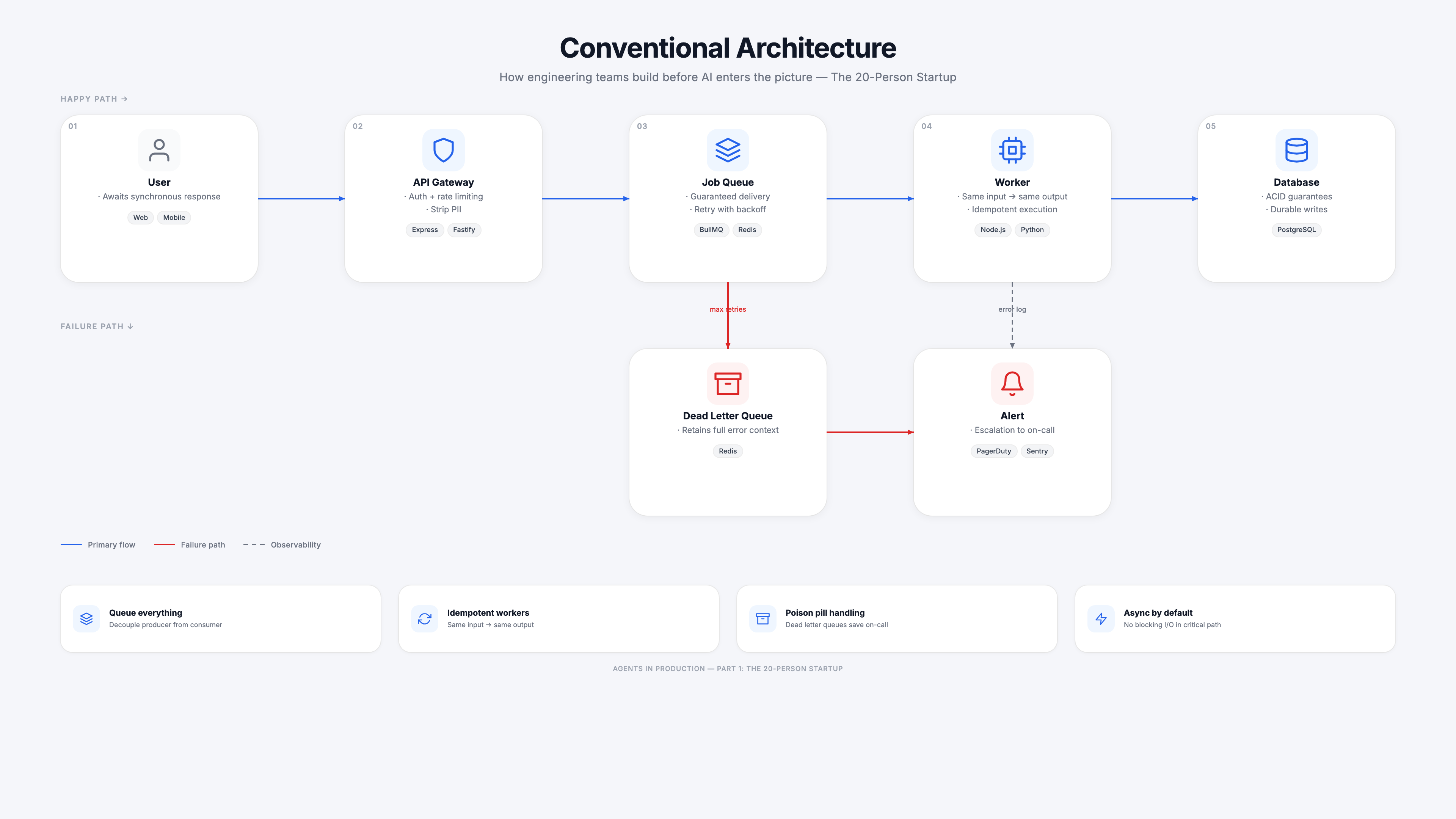
Before AI enters the picture, the typical startup API stack looks like this: a gateway handles auth and rate limiting, incoming work gets pushed to a job queue, workers pull from the queue and process idempotently, results land in the database. Failed jobs retry with backoff and eventually move to a dead letter queue. On-call gets paged.
This is not a naive setup. It took the team months to build the discipline to make workers idempotent. The dead letter queue saved them twice from bad deploys. The queue decouples the API response from the actual processing, so the user gets a fast 202 while work happens in the background.
// What a well-structured queue worker looks like
async function processJob(job: Job): Promise<void> {
const existing = await db.findResult(job.data.requestId);
if (existing) return; // idempotent — already processed
const result = await heavyOperation(job.data);
await db.saveResult({
requestId: job.data.requestId,
result,
processedAt: new Date(),
});
}
// BullMQ wiring — exponential backoff, DLQ on exhaustion
const worker = new Worker('jobs', processJob, {
connection: redis,
attempts: 5,
backoff: { type: 'exponential', delay: 2000 },
});
The key insight: this architecture already handles the hard parts. The queue guarantees delivery. The idempotency guard prevents double-processing. The dead letter queue retains context for forensics. The foundation for adding AI is already here.
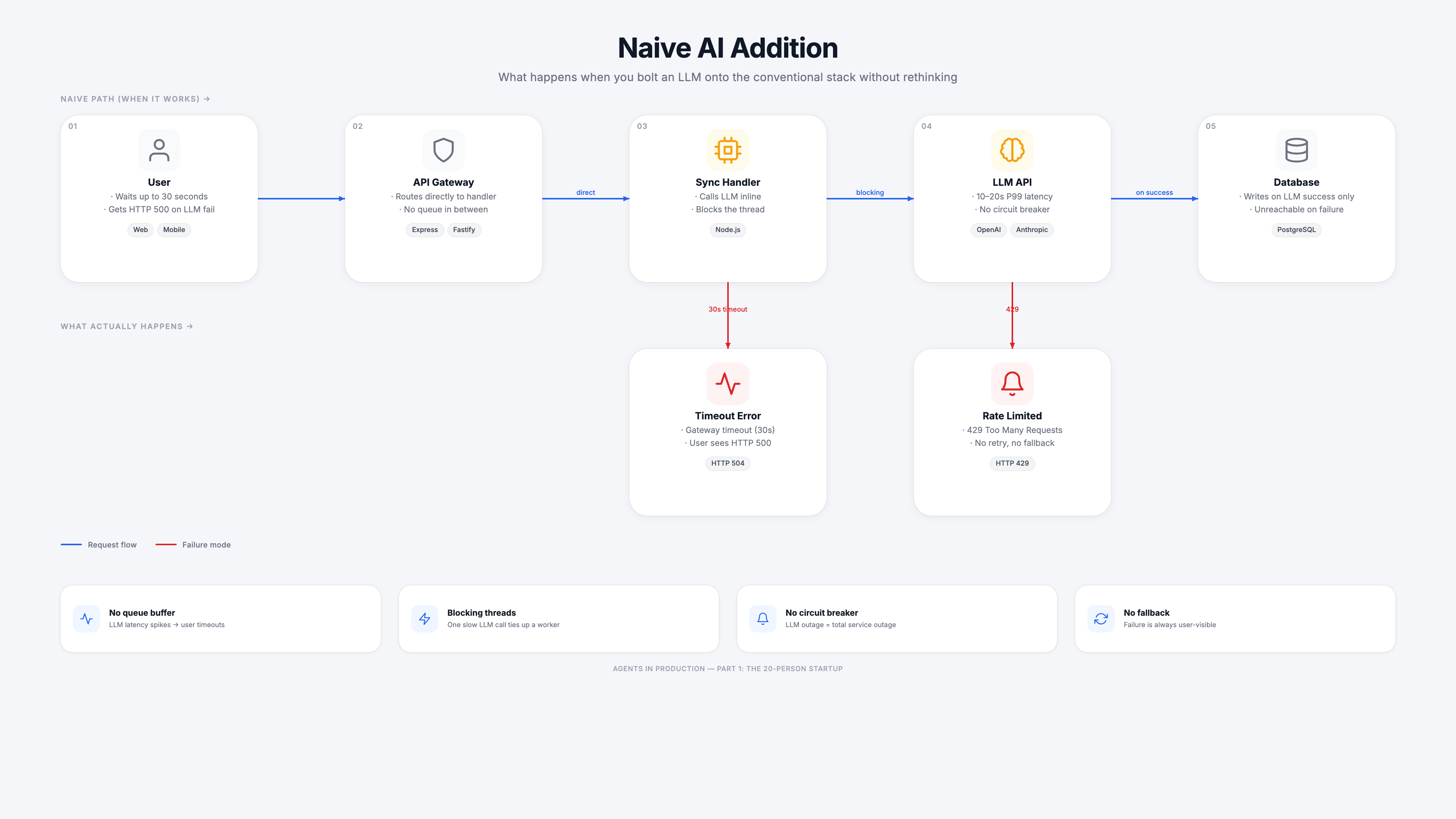
What the naive LLM addition looks like
The mistake teams make is treating the LLM call like a fast database query. A developer opens the request handler, adds three lines to call the LLM API inline, and deploys. The feature works in testing because staging traffic is light and P50 latency looks fine.
// The anti-pattern: synchronous LLM call in the request handler
app.post('/api/analyze', async (req, res) => {
const { text } = req.body;
// This blocks the thread for 10-20 seconds at P99
const analysis = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [{ role: 'user', content: text }],
});
const result = await db.save({ text, analysis: analysis.choices[0].message.content });
res.json({ id: result.id, analysis: result.analysis });
});
Three things break simultaneously under real load:
Thread starvation. Node.js event loop handles I/O asynchronously, but awaiting a 15-second LLM response still holds the handler open. With 50 concurrent requests, you have 50 open connections waiting on LLM responses. Your server's connection pool exhausts. New requests queue at the load balancer. Users see timeouts before the LLM even responds.
Gateway timeouts. Most load balancers and API gateways have a 30-second timeout. The LLM P99 latency for a complex prompt is 18 to 25 seconds. Any request that hits a slow model response or brief API hiccup fails with HTTP 504, even though the LLM eventually responds successfully. The response arrives after the client gave up.
No retry or fallback. When the LLM API returns a 429 rate limit, the request fails immediately with HTTP 500. There is no retry, no fallback to a cached result, no degraded response. The user sees an error. The database write never happens.
// What production logs look like after the naive addition [ERROR] POST /api/analyze 504 Gateway Timeout (31,204ms) [ERROR] POST /api/analyze 500 Internal Server Error - 429 Too Many Requests [ERROR] POST /api/analyze 504 Gateway Timeout (30,891ms) [ERROR] POST /api/analyze 500 Internal Server Error - 429 Too Many Requests [ERROR] Worker queue depth: 847 (normal: ~12)
The queue depth number is the tell. The original workers process fast — database writes, simple transforms. Add one slow synchronous LLM call to the hot path and the queue backs up because handlers are all blocked waiting on the LLM.
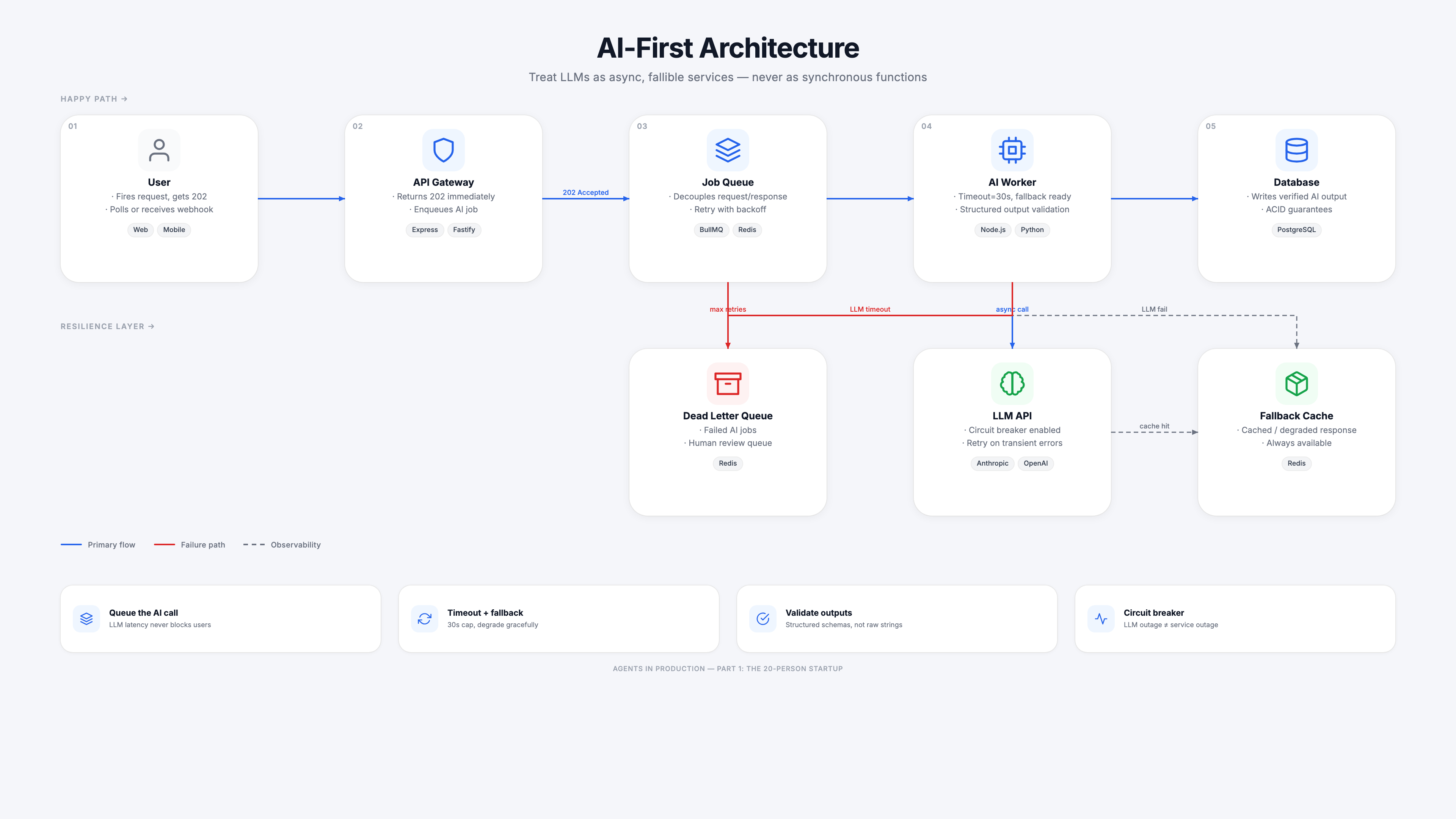
The corrected architecture
The fix is conceptual before it is technical: treat the LLM as an async, fallible external service, not as a fast local function. The same principles that make your database writes reliable apply here — queue the call, handle timeouts explicitly, have a fallback.
Four changes close most of the gap:
1. Queue the AI call. The request handler does one thing: validates input, enqueues an AI job, returns 202 immediately. LLM latency never touches the user's request cycle. The user polls for the result or receives a webhook.
// Handler: fast, non-blocking, immediate 202
app.post('/api/analyze', async (req, res) => {
const { text } = req.body;
const jobId = ulid();
await aiQueue.add('analyze', { jobId, text }, {
jobId,
attempts: 5,
backoff: { type: 'exponential', delay: 3000 },
});
res.status(202).json({ jobId, pollUrl: `/api/jobs/${jobId}` });
});
// Worker: processes async, off the hot path
const aiWorker = new Worker('ai-jobs', async (job) => {
const { jobId, text } = job.data;
const result = await callLlmWithTimeout(text, { timeoutMs: 30_000 });
const validated = validateOutput(result); // parse structured schema
await db.saveResult({ jobId, result: validated });
}, { connection: redis, concurrency: 5 });
2. Timeout with a fallback. Set a hard timeout on the LLM call — 30 seconds is a reasonable upper bound. When it fires, write a degraded response from a cache of prior results rather than failing with an error. The user gets a slightly stale answer instead of an error page.
async function callLlmWithTimeout(
text: string,
options: { timeoutMs: number }
): Promise<string> {
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), options.timeoutMs);
try {
const response = await openai.chat.completions.create(
{ model: 'gpt-4o', messages: [{ role: 'user', content: text }] },
{ signal: controller.signal }
);
return response.choices[0].message.content ?? '';
} catch (err) {
if (err instanceof Error && err.name === 'AbortError') {
// Timeout — return cached fallback
const cached = await fallbackCache.get(hashText(text));
if (cached) return cached;
throw new Error('LLM timeout and no cache hit');
}
throw err;
} finally {
clearTimeout(timer);
}
}
3. Validate LLM outputs. LLMs do not return reliable JSON. They hallucinate fields, omit required keys, and occasionally return prose when you asked for a schema. Parse and validate every response before writing it to the database. Reject it back to the queue for retry if it fails validation — do not write garbage.
import { z } from 'zod';
const AnalysisSchema = z.object({
sentiment: z.enum(['positive', 'negative', 'neutral']),
confidence: z.number().min(0).max(1),
summary: z.string().min(10).max(500),
topics: z.array(z.string()).min(1).max(10),
});
function validateOutput(raw: string): z.infer<typeof AnalysisSchema> {
const parsed = JSON.parse(raw); // throws on invalid JSON
return AnalysisSchema.parse(parsed); // throws on schema mismatch
}
4. Circuit breaker on the LLM client. If the LLM API starts returning errors consistently, stop sending requests immediately instead of hammering a degraded service. Open the circuit after 5 consecutive failures, half-open after 60 seconds to test recovery. This prevents a LLM outage from exhausting your retry budget and backfilling your queue.
import CircuitBreaker from 'opossum';
const breaker = new CircuitBreaker(callLlmWithTimeout, {
timeout: 30_000,
errorThresholdPercentage: 50, // open after 50% failure rate
resetTimeout: 60_000, // half-open after 60s
volumeThreshold: 5, // minimum requests before tripping
});
breaker.on('open', () => {
logger.warn('LLM circuit breaker OPEN — using fallback cache');
metrics.increment('llm.circuit_breaker.open');
});
breaker.on('halfOpen', () => {
logger.info('LLM circuit breaker half-open — testing recovery');
});
What the incident looked like in hindsight
The 2 AM incident was not caused by a bad LLM API. The LLM was working. The problem was that the startup's request handler had no concept of the LLM being slow or unavailable. When the API returned a 429 at 11 PM, the handler threw an unhandled error, the job was never queued, and the queue depth metric — which would have paged on-call — stayed at zero.
By 2 AM, 847 user requests had silently failed. The database showed no errors because no writes had been attempted. The first signal was a support ticket.
The corrected architecture would have caught this at the circuit breaker and surfaced it in the dead letter queue within minutes. The user would have received a degraded response from the fallback cache. On-call would have seen the circuit trip in metrics before any user noticed.
The foundation was already there. The queue, the DLQ, the monitoring. The only thing missing was treating the LLM like the external service it is.
Where this falls short at the next scale
These four changes handle a 20-person startup at moderate load. They do not handle multi-step agent workflows, where one LLM call's output feeds the next. They do not handle structured agent loops with tool use, where a single user action may trigger 8 to 15 LLM calls in sequence. And they do not handle the observability problem: knowing which LLM call in a chain caused a bad final output.
Part 2 covers the step-function complexity that hits when you move from single LLM calls to multi-step agent workflows — what breaks, what the production-grade pattern looks like, and which observability primitives you need before you can debug agents at all.